
ادغام فناوری های پیشرفته مانند هوش مصنوعی و یادگیری ماشین در تحقیقات شما فقط یک روند نیست، بلکه یک ضرورت است.
در Labguru، ما دائماً در حال بررسی ادغام فناوریهای جدید برای سادهسازی و بهبود عملیات آزمایشگاهی و فرآیندهای مدیریت دادهها هستیم. بنابراین هوش مصنوعی مولد کجا در پشته فناوری ما قرار می گیرد؟ و کجا می تواند در زمان/منابع شما صرفه جویی کند؟
در این وبلاگ، ما نشان میدهیم که چگونه میتوان از هوش مصنوعی برای مدیریت حجم فزاینده دادههای علمی با غنیسازی اشیاء Labguru خود با استفاده از ترانسفورماتور از پیش آموزشدیده (GPT) برای شناسایی اشیای نامگذاری شده (NER) استفاده کرد.
مزایای استفاده از GPT همراه با Labguru
GPT (Generative Pre-trained Transformer) یک مدل زبان هوش مصنوعی پیشرفته است که توسط OpenAI توسعه یافته است. این مدل برای درک و تولید متن انسانی بر اساس آموزش بر روی مجموعه داده های متنوع و گسترده کار می کند.
توانایی GPT برای پردازش و تفسیر حجم زیادی از متن، آن را به ابزاری قدرتمند در وظایف پردازش زبان طبیعی، از جمله تشخیص اشیاء نامگذاری شده، که هنگام برخورد با ادبیات علمی پیچیده ضروری است، تبدیل میکند.
شناسایی موجودیت نامگذاری شده (NER) یک جنبه حیاتی از پردازش زبان طبیعی (NLP) است که بر شناسایی و طبقه بندی اطلاعات معنی دار در متن متمرکز است. این شامل کشف اشیاء خاص، مانند نام افراد، سازمانها، مکانها و اصطلاحات فنی مرتبط با گفتمان علمی است.
با استفاده از قابلیتهای پردازش زبان پیشرفته GPT، میتوانیم مستقیماً از آن برای شناسایی نهادهای نامگذاری شده (NER) در متون علمی استفاده کنیم. این رویکرد به GPT اجازه می دهد تا اطلاعات ضروری مانند اصطلاحات خاص، نقاط داده و موجودیت های مرتبط را شناسایی و استخراج کند. این کاربرد مستقیم GPT در وظایف NER سازماندهی و مدیریت داده های علمی را ساده می کند، کارایی و کارایی را افزایش می دهد. دقت در مدیریت داده های پژوهشی
کاربرد عملی: استخراج کلمات کلیدی و برچسب گذاری در Labguru
مرحله 1: یک سند را با استفاده از Labguru API واکشی کنید
ابتدا، بیایید یک مقاله علمی از فضای کاری Labguru خود بگیریم.
در زیر تصویری از مقاله مورد علاقه من از فضای کاری Labguru من است:
در اینجا یک قطعه کد پایتون برای بازیابی شی کاغذ از API Labguru آمده است:
import requests
import json
# Authenticate to get your Labguru token
LABGURU_BASE = 'https://your_labguru_domain'
auth_url = f"{LABGURU_BASE}/api/v1/sessions.json"
credentials = {'login': 'your_email', 'password': 'your_password'}
auth_response = requests.post(auth_url, json=credentials)
auth_data = json.loads(auth_response.text)
LABGURU_TOKEN = auth_data['token']
# Replace with the id of the paper you wish to fetch
paper_id = 2
# Fetch a specific paper
url = f"{LABGURU_BASE}/api/v1/papers/{paper_id}"
payload = {'token': LABGURU_TOKEN}
response = requests.get(url, payload)
paper = response.json()
print(paper)
مرحله 2: کلمات کلیدی را با GPT OpenAI استخراج کنید
سپس از GPT OpenAI برای NER برای استخراج کلمات کلیدی از چکیده مقاله استفاده می کنیم:
import openai
OPENAI_KEY = "your_openai_api_key_here" # Replace with your OpenAI API key
OPEN_AI_BASE = "https://api.openai.com/v1"
# Let's organize the input for the completions task
instructions = """
Your task is to provide a list of up to 5 tagging options to tag a given
text in an ELN system.
A tag can be a 1 word term/phrase and maximum 2 words for 1 tag.
Response format would be a JSON of an array of tags as strings -
["tag_a", "tag_b",...]
"""
prompt = f"Extract keywords from this text: {paper['review']}"
payload = {
"model": "gpt-3.5-turbo",
"response_format": { "type": "json_object" },
"messages": [
{"role": "system", "content": instructions},
{"role": "user", "content": prompt}
]
}
headers = {
'Content-Type': 'application/json',
'Authorization': f"Bearer {OPENAI_KEY}"
}
url = f"{OPEN_AI_BASE}/chat/completions"
response = requests.post(url, headers=headers, data=json.dumps(payload))
tags = response.json()['choices'][0]['message']['content']
print(f"Suggested Tags for the paper -> {tags}")
tags = json.loads(tags)['tags']
# output:
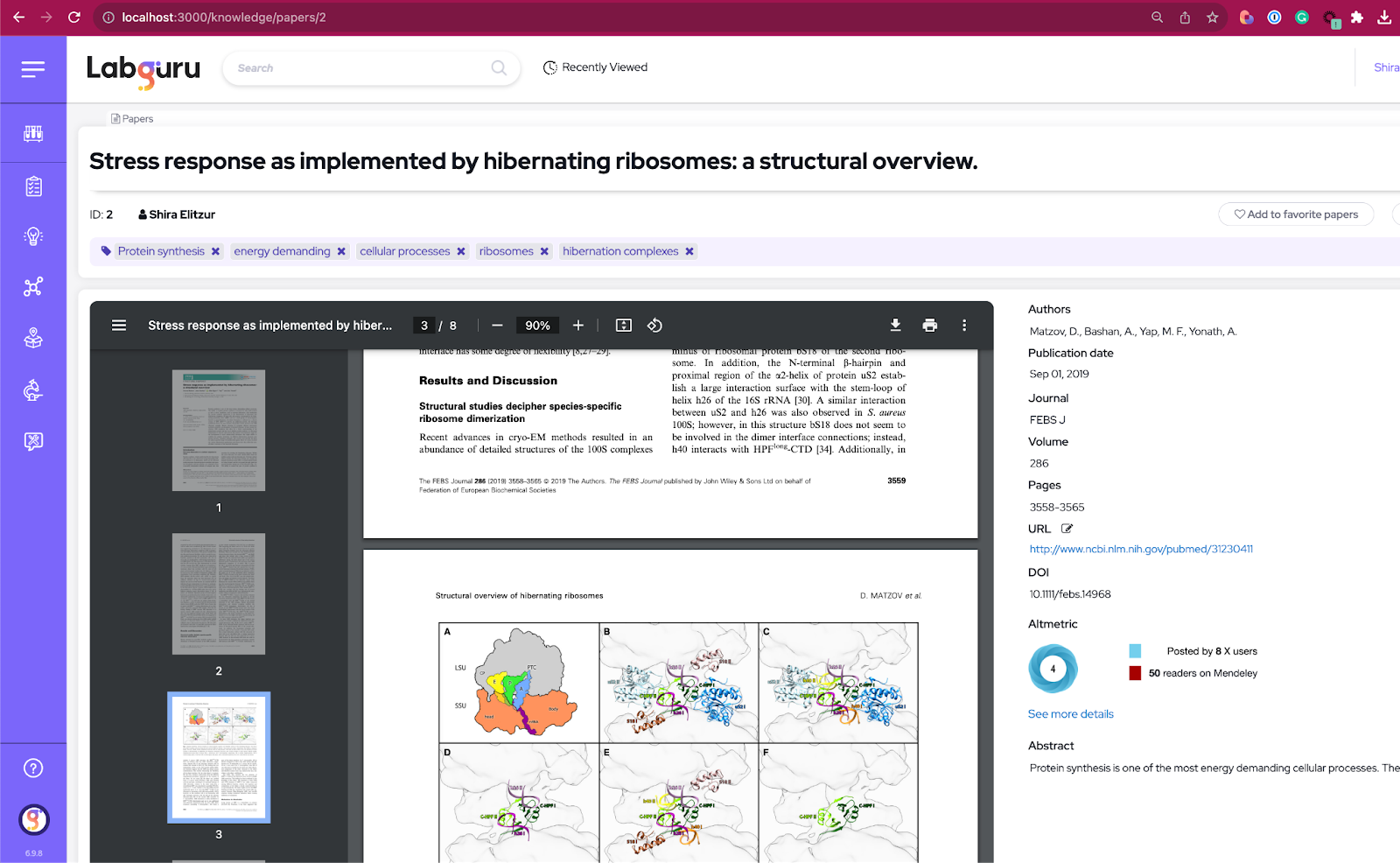
# > Suggested Tags for the paper -> ["Protein synthesis", "energy demanding", "cellular processes", "ribosomes", "hibernation complexes"]مرحله 3: کلمات کلیدی را به عنوان برچسب در Labguru اضافه کنید
در نهایت، بیایید این کلمات کلیدی استخراج شده را به عنوان برچسب به مقاله در Labguru اضافه کنیم:
url = f"{LABGURU_BASE}/api/v1/tags"
for tag in tags:
data = {
"item": {
"tag": tag,
"class_name": paper['class_name'],
"item_id": paper['id']
},
"token": LABGURU_TOKEN
}
response = requests.post(url, json=data)
print(f"New Tag '{tag}' was added for paper #{paper['id']}")
# output:
# > New Tag 'Protein synthesis' was added to paper #2
# > New Tag 'energy demanding' was added to paper #2
# > New Tag 'cellular processes' was added to paper #2
# > New Tag 'ribosomes' was added to paper #2
# > New Tag 'hibernation complexes' was added to paper و در اینجا برچسب های جدید در مقاله Labguru آمده است:
مزایا و بینش های آینده
این ادغام چندین مزیت دارد:
- کارایی: خودکار کردن فرآیند استخراج و برچسب گذاری باعث صرفه جویی در زمان ارزشمند تحقیق می شود.
- سازماندهی داده ها: بهبود برچسب گذاری کلمات کلیدی منجر به سازماندهی و جستجوی بهتر در Labguru می شود.
- مقیاس پذیری: در حالی که انجام این مراحل به صورت دستی برای 1-2 سند بسیار آسان به نظر می رسد، این روش را می توان به طور خودکار برای تعداد زیادی از اسناد اعمال کرد و به تجزیه و تحلیل داده های در مقیاس بزرگ کمک کرد.
با نگاهی به آینده، امکانات بسیار زیاد است. از اصلاح بیشتر فرآیند NER تا ادغام مدلهای پیشرفتهتر هوش مصنوعی برای تجزیه و تحلیل عمیقتر دادهها، پتانسیل تقویت Labguru با هوش مصنوعی نامحدود است.
نتیجه
با ترکیب Labguru با قدرت GPT و LLM، سطح جدیدی از کارایی و سازماندهی را در تحقیقات خود باز می کنید. امیدواریم این راهنما به شما انگیزه دهد تا پتانسیل هوش مصنوعی را در فرآیندهای مدیریت داده خود کشف کنید.
ما اخیرا آخرین نوآوری خود را معرفی کردیم، دستیار Labguruچت ربات پیشرفته هوش مصنوعی که توسط OpenAI یا LLM داخلی، طراحی شده تا دانشمندانی مانند شما را قادر سازد تا پیچیدگی های تحقیقات مدرن را با سهولت و کارایی بی نظیر دنبال کنند.
برای یادگیری اینکه چگونه می توانید کارایی گردش کار تحقیقاتی خود را با دستیار Labguru ساده و بهبود بخشید –
